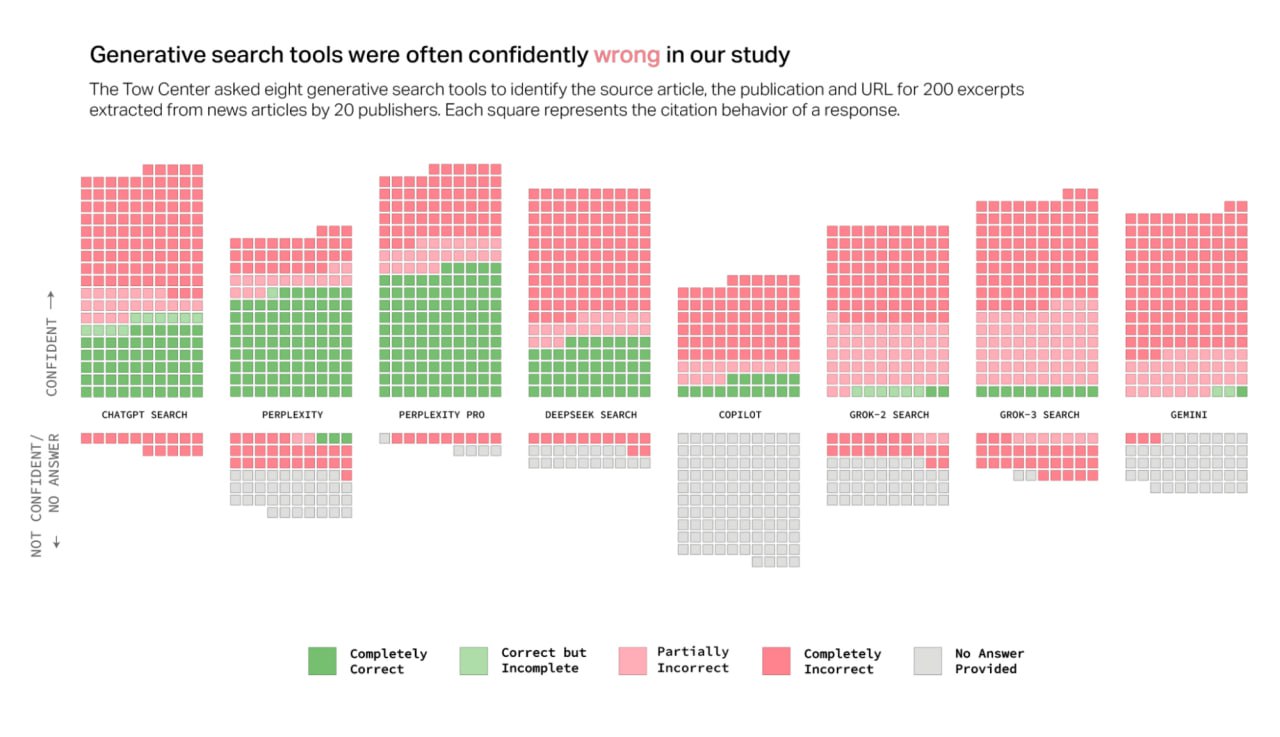
Tow Center провели дослідження-порівняння 8 пошукових систем на базі AI щодо їх здатності точно цитувати джерела новин і відповідати на запити про новини, виявивши значні недоліки на всіх платформах.
Були задіяні наступні генеративні пошуковики:
🟢ChatGPT 🟢Perplexity 🟢Perplexity Pro 🟢Copilot 🟢Gemini 🟢DeepSeek 🟢Grok 2 🟢Grok 3
Виявилось, що чат-боти постійно надають невірну або сфабриковану інформацію, часто з невиправданою впевненістю, і їм важко належним чином подавати посилання на оригінальні статті новин. Примітно, що преміум-версії чат-ботів іноді показували більш впевнено неправильні відповіді, ніж безкоштовні альтернативи.
Вказані вище інструменти відповіли неправильно на 60% запитів. Найбільш коректно відповідав Perplexity — 37% відповідей у нього некоректні. Grok 3 — найгірше — 94% відповідей некоректні. При цьому вони всі постійно демонстрували впевненість у своїх відповідях.
А навіть коли відповідали коректно, не могли ідентифікувати правильно джерело інформації.
Також були випадки, коли AI-боти обходили обмеження на сканування веб-сайтів і неправильно присвоювали контент, навіть незважаючи на ліцензійні угоди з видавцями новин. Дослідження підкреслює брак прозорості та потенційну шкоду як для новинних організацій, так і для користувачів. Особливо цим "страждає" Perplexity.