HouseFresh, який Google колись обвалив на 95%, повернув трафік понад колишній пік, AI Overviews у Discover увімкнулися вже в 13 мовах, а зеро-клік у пошуку перевалив за дві третини. Окремо великий блок від українських колег: mova.today, бот апдейтів Google від Олексія Матузного, реєстрація торгової марки Listicle і перше Cursor Cafe в Україні. І це ще не все.
Три найголовніші новини тижня
-
AI Overviews у Google Discover розкотилися вже на 13 мов. Damien Andell перевірив 101 мову станом на 23 червня: лідери Корея (13 карток, до 21 джерела) і Тайвань (10 карток, до 30 джерел), далі Велика Британія 7, США 6. Працюють два окремі канали: один віддає статейні AI Overviews, другий відео з YouTube. Британія увімкнула статейні AIO 11 червня і за два дні вийшла на плато близько 1000 карток на день, а от відео-AIO там ще немає (вони активні в США, Кореї, Індонезії, Індії та Бразилії). Видавцям варто цілитися в головну статтю, яку AI ставить згори, бо проста згадка в списку джерел дає значно менше.
-
Не минуло й трьох років, а HouseFresh повернувся з того світу. Сайт, який колись гучно писав, як Google вбиває незалежні медіа, і який пару років лежав похований під Helpful Content Update, за словами Chris Long, повернув собі трафік. Восени 2023 цей апдейт обвалив його на 95%, з 4000 до 200 відвідувачів на день. Далі два роки відбудови: контент, власний YouTube-канал, колаборація з Linus Tech Tips, частковий відскок на core update у червні-липні 2025 і повне відновлення понад колишній пік аж до жовтня 2025. Повернутися допомогло й те, що Google прибив накрутку чужої репутації й вирівняв поле для сайтів-оглядів. Поряд Lily Ray показала, що RickSteves.com різко наростив видимість і цитування в AI Overviews уже після травневого core update. Rick Steves десятиліттями по чотири місяці на рік ходить тими маршрутами і щороку оновлює путівники, тисячі сторінок безкоштовного контенту, без афілейт-впливу, бо заробляє книгами й турами. AI Overviews цитують і його сайт, і його YouTube, і TikTok. Той самий сайт, який Google пару років тримав за некорисний, тепер зненацька став у нього корисним.
-
Зеро-клік, тобто пошук, після якого людина не переходить на жоден сайт, бо відповідь уже у видачі, перевалив за дві третини. Rand Fishkin із даними Similarweb порахував його по шести країнах за січень-квітень 2026, від 62% у Німеччині до майже 70% у Британії. Але сама цифра оманлива, бо зеро-клік не означає, що людина дістала відповідь. У США після пошуку без кліку найчастіше роблять ще один пошук (29%), тобто переформульовують, а у Британії навпаки, там і не клікають, і найчастіше завершують сесію задоволеними. Найефективніші французи, вони знаходять і зупиняються. Європейці загалом клікають помітно частіше за американців і британців, німці аж на 20% більше, і SparkToro припускає, що їх тримає клікаючими тиск ЄС на Google за самопросування у видачі, хоча Канада з близькими до ЄС цифрами натякає, що діють й інші чинники. А ще 7-9% усіх кліків, що таки стаються, ведуть назад на сайти самого Google, на YouTube чи Карти. Жодна країна вже не дає й 300 переходів у відкритий веб на тисячу пошуків. Раніше ми показували інший бік того ж тренду. Microsoft визнала, що AI забирає кліки, а Ahrefs нарахував зрізання кліків по першому результату на 58%.
Новини українських SEOшників
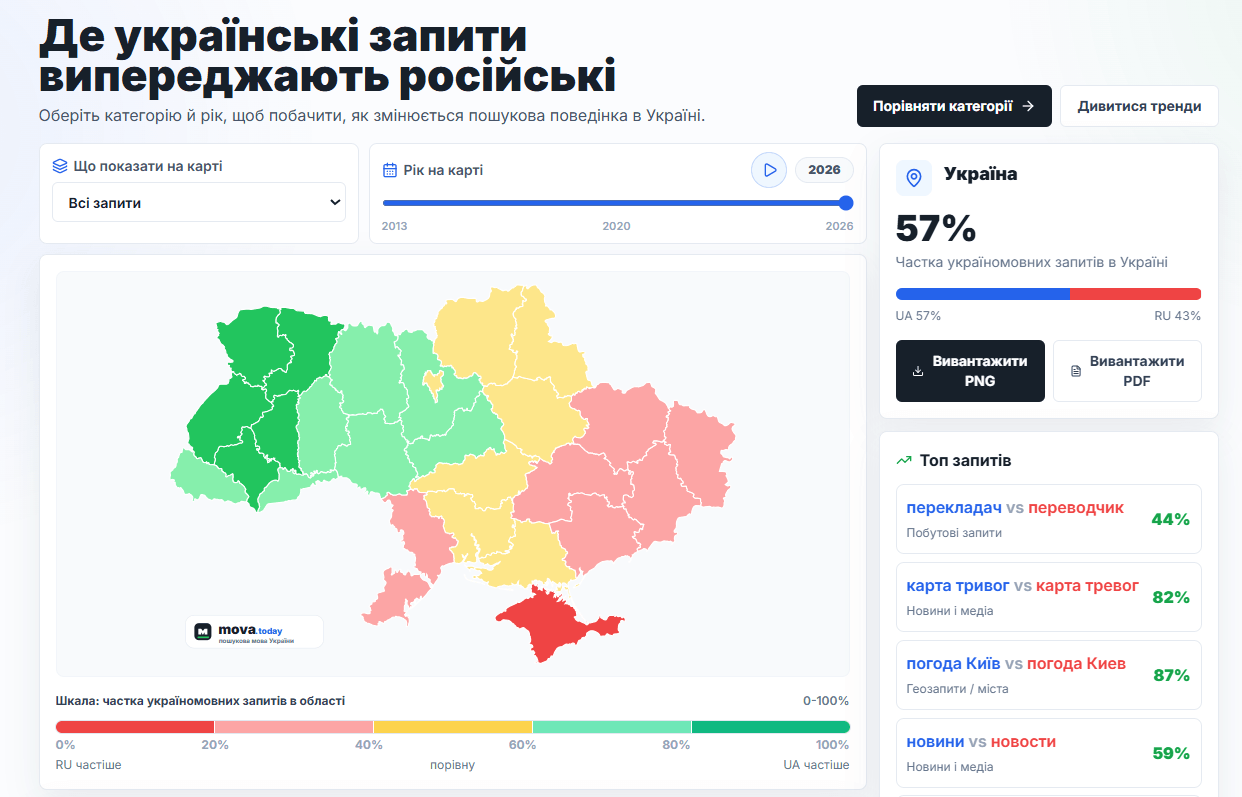
- mova.today показує динаміку українських проти російських запитів у Google (через допис @vibeandseo). Український проєкт на базі Google Trends, 1229 запитів з 2013 по 2026. Станом на 2026 українською в Україні роблять 57% запитів. Захід країни вже майже весь україномовний, схід і південь досі тяжіють до російської. А розрив по конкретних запитах величезний: погода Київ проти погода Киев це 87% на користь української, новини проти новости 59%, а от перекладач проти переводчик лише 44%.
-
Олексій Матузний запустив бота, що стежить за апдейтами Google, @sneex_channel_bot. Бот одразу повідомляє, коли Google запускає апдейт (core, spam, reviews), коли він завершився і скільки тривав, і до кожного дає короткий розбір, на що дивитися: E-E-A-T, spam-політики, winners та losers. Це старт, далі автор додаватиме більше SEO-інструментів прямо в бота.
-
Alex Savy показав, як гнати трафік із Reddit без посилань у коментарях, через додатки. Reddit активно просуває власну платформу додатків Devvit, де можна зробити інтерактивний інструмент прямо в сабреддіті. Компанія Compare the Leaf вбудувала в свій саб квіз, що ставить кілька запитань і вже потім підбирає рекомендацію з посиланнями на сайт, і такому люди довіряють більше, ніж голому посиланню в коментарі. Свій калькулятор чи квіз, корисний спільноті й без явної реклами, можна так само пропонувати в релевантних сабах, а посилання лишати внизу.
-
Український провайдер admixglobal зареєстрував у патентному офісі США торгову марку Listicle. Нагода згадати, чому всі кинулися на лістикли: за Ahrefs, саме на статті-добірки формату best X припадає 43,8% усіх цитувань у чатах. Тож лінкбілдери тепер продають той самий старий лінкбілдинг під виглядом AI-оптимізації, просто звучить для клієнта переконливіше. А оскільки 74% споживачів уже користуються AI-пошуком перед покупкою, клієнти масово тестують такі агенції, і хто лишився на простій закупівлі посилань, втрачає замовників.
-
30 червня в Києві відбудеться перше в Україні Cursor Cafe. Кафе КультМотив на Подолі орендоване під бренд Cursor з 12:00 до 22:00. Можна прийти кодити з безкоштовними кредитами Cursor для тих, хто щось будує, або просто на каву й спілкування. О 18:00 буде пітч про амбасадорську програму Cursor, бо в Україні шукають другого амбасадора. Місць обмаль.
Анонси чужих заходів не є рекламою і робляться для нетворкінгу української SEO-спільноти, усі вони в нашому календарі подій.
Як влаштований AI-пошук
-
Suganthan Mohanadasan почитав мережевий трафік ChatGPT і показав, як той обирає джерела. У відповідях є поле з назвою каналу, звідки взято результат: ліцензовані видавці (Reuters, WSJ), сервіс збору даних Bright Data для комерційних запитів, сервіс Oxylabs для регіонального контенту і звичайна видача як база. Reddit виявився найцитованішим доменом, хоча YouTube ChatGPT відкриває частіше, бо YouTube віддає лише метадані, а Reddit готовий текст. Ціни й характеристики при цьому мають бути звичайним текстом у HTML, не підвантаженим скриптом і не картинкою, бо модель буквально шукає на сторінці символи валют. Услід за цим RESONEO розширили своє безкоштовне розширення для Chrome, і тепер воно витягує і цей канал джерела, і категорію наміру, яку ChatGPT присвоює запиту, і розбивку типів цитувань.
-
Dan Petrovic розклав, чим відрізняються джерело, цитування і згадка в AI-відповіді. Спочатку запит розгалужується на кілька пошуків, потім система відбирає за релевантністю джерела, додає їх у контекст моделі, і вже модель генерує відповідь зі згадками брендів у певному порядку та з цитуваннями на джерела. Бути цитованим джерелом і бути згаданим у тексті відповіді це різні речі, вони корелюють, але не на сто відсотків.
-
Він же показав, що Gemini має вимірювану упередженість проти китайських брендів. Пробивши модель мільйони разів, він побудував мережу авторитету брендів, де BYD опинився аж на 935 місці. На запиті про безпечний електро-кросовер для сім'ї він переписав текст сторінки BYD, замість переліку фіч поставив незалежний квантифікований факт про п'ятизірковий рейтинг безпеки ANCAP і високу оцінку захисту дітей, і цим зрушив видачу на користь бренду і в Gemini, і в GPT. Зауважує, що оптимізація була агресивна і нашкодила іншим аспектам сторінки, тож як готовий бриф не годиться. Знову те саме, AI краще сприймає незалежні цифри й оцінки, ніж довгі списки можливостей.
-
Google показав підхід Token Factory для великих рекомендаційних систем, зокрема для YouTube. Замість описувати кожен сигнал про користувача текстом (історія переглядів, час перегляду, канал, контекст), система стискає їх у компактні навчені вектори, які модель розуміє напряму. Це дозволяє врахувати довшу історію переглядів, не роздуваючи запит, точніше передбачати кліки і дешевше працювати. По суті це місток між класичними рекомендаціями зі структурованими сигналами і трансформерами, обмеженими довжиною контексту. Стосується YouTube, TikTok, Netflix і Google Discover.
Нові шляхи видимості в Discover
- У Google Discover запрацював третій шлях потрапити до читача. Фіча Tailor Your Feed, тепер перейменована на Add topics to your feed, дає користувачеві формувати стрічку запитами звичайною мовою, поверх звичних неявних сигналів поведінки. Система розбиває запит на уточнені підзапити, які піднімають релевантний контент незалежно від попередньої популярності сайту. Для нішевих видавців це шанс, бо малий сайт може дійти до людини, що попросила його тему, без історії в Discover і без кнопки підписки. Damien Andell помітив, що кожна така картка має позначку You asked to see, а його пост про ці підзапити лайкнув віцепрезидент пошуку Google Rajan Patel. На сторінці важать чіткі сутності й природна питальна лексика.
Видавці й AI: хто на кому заробляє
-
Google вимагає від видавців віддати права на контент за участь в AI-фічах Google News. Програма з грудня, перші партнери Washington Post і Guardian, обіцяє промо в AI-оглядах Google News і в Gemini, що цінно на тлі падіння пошукового трафіку вдвічі. А підступ у тому, що серед цих прав є і потенційне тренування AI-моделей на їхньому контенті. А хто не погодиться, той зрештою втратить виплати за старою програмою Showcase, яку Google планує закрити.
-
Тим часом Time і Axios уже монетизують свою помітність в AI. Операційний директор Time каже, що люди заходять на сайт, а боти йдуть на окрему спрощену текстову сторінку, і компанія робить продукт, який узагалі не публікується у вебі й існує суто для ботів, бо ті все частіше і купують, і впливають на покупки. Туди ж Time направляє платний branded-контент. Axios робить ставку на коротку подачу з головним угорі, бо саме так читають LLM. За даними Press Gazette, 84% AI-цитувань ідуть із контенту видавців.
-
Suno навчали на 21 мільйоні треків, зібраних із мережі без дозволу. За розслідуванням Alex Reisner у The Atlantic, Suno визнає, що брав захищену музику, але називає це fair use, мовляв, модель учиться на абстрактних патернах і не копіює конкретні пісні. Для будь-кого іншого це було б піратством. Sony та інші лейбли отримають виплату, а самі артисти навряд.
-
Опитування 1800 журналістів від Cision (State of the Media 2026) показало, що AI-інструменти як джерело ідей для матеріалів використовують лише 10% із них, тоді як на контент від піарників спираються 66%. На SEO-оптимізацію припадає лише 17% усього їхнього використання генеративного AI.
Як міряти AI-видимість
-
John Mueller пояснив, як Search Console рахує покази в AI. Покази рахуються за посиланнями на ваш сайт, які показані в AI Overviews і AI Mode. Сам favicon під питанням, але якщо лінк веде на сторінку сайту, він зараховується. Якщо лінк треба розкрити, щоб побачити, він рахується лише коли користувач це зробив. Заразом новий звіт про AI-продуктивність у Search Console котиться вже не тільки на британські акаунти, а на ширше коло.
-
З'явився фреймворк Quarterly GEO Scorecard для виміру присутності в AI-пошуку поквартально. Ядро це частка згадок бренду в ChatGPT, Claude, Gemini, Perplexity та AI Overviews, з розбивкою по етапах воронки. Методологія проста. Зафіксувати набір з 50 до 150 промптів, тричі прогнати кожен на кожному рушії і тримати ту саму методику з кварталу в квартал, а рух у 5 і більше пунктів вважати справжнім сигналом.
-
Ethan Smith з Graphite на кейсі n8n показав, що атрибуція по останньому кліку ховає трафік з AI. Більшість конверсій з AI це зеро-клік, коли людина побачила бренд у відповіді й пішла напряму чи через брендовий пошук. Якщо питати після конверсії How Did You Hear About Us, цифри інші: для AEO 0,9% по останньому кліку проти 9% у самозвіті, для SEO 7% проти 30%. Самозвіт теж недосконалий через хибну пам'ять і вибір лише одного каналу, але останній клік бреше сильніше.
Контент і ранжування
-
Carolyn Shelby пояснює, чому більше контенту псує ваше SEO. AI-пошук ріже сторінки на окремі шматки тексту й винагороджує чіткість понад обсяг, тож гонитва за кількістю постів шкодить. Замість швидкості вона радить щільність авторитету: зливати дублюючі матеріали, посилювати наріжні сторінки й осмислено їх перелінковувати.
-
У не-англомовних країнах Google AI дедалі частіше підсовує англійські треди Reddit у машинному перекладі. За аналізом 64,77 мільйона цитувань Reddit у 20 країнах, такі перекладені треди складають 40-73% усіх згадок Reddit у видачі Німеччини, Швеції чи Норвегії. ChatGPT майже прибрав це за місяць, з 6,14% до 0,66%, а Google тримає стабільні 8-14%. Тобто в умовній німецькій видачі AI підставляє перекладений англійський Reddit замість місцевих джерел, і мовний бар'єр, який раніше захищав локальні сайти, на AI-поверхнях Google впав.
-
Wikipedia безстроково заблокувала редагування своєму співзасновнику Larry Sanger. Причина в canvassing, бо він анонсував свій проєкт про інтелектуальну різноманітність 93 тисячам підписників в X, а правила забороняють залучати сторонніх для впливу на контент. Sanger понад десять років звинувачує Wikipedia в лівому ухилі й назвав бан судилищем натовпу. Для нас це важливо тому, що Wikipedia одне з найбільших джерел для мовних моделей, близько 30% цитувань ChatGPT, тож чистки й упередженість у головному AI-джерелі прямо впливають на те, що відповідає AI.
-
Chris Green розклав приховану економіку рішення будувати чи купувати SEO-інструменти. Рахувати треба цінність за трьома чинниками: вартість з урахуванням прихованої праці своєї команди, чи дає це перевагу над конкурентами і чи зможете ви це підтримувати. Готові рішення варто купувати, а будувати лише там, де у вас унікальні вимоги.
-
Darren Shaw на кейсі клієнтки показав, що прибрати адресу з Google Business Profile означає вбити локальні позиції. Клієнтка прибрала адресу і виставила зону обслуговування на всі США, після чого на карті ранжування її буквально закинуло в океан, а всі позиції впали. Щойно адресу повернули, наступного дня все відновилося, причому переверифікацію Google не вимагав. Питання відкрите, чому Google так б'є по бізнесах із зоною обслуговування, баг це чи навмисно.
AI-індустрія
-
OpenAI випустила звіт про те, як агенти змінюють роботу на прикладі самої себе. До серпня 2025 середній працівник витрачав на кодового агента Codex менше 10% запитів, а тепер це основний AI-інструмент кожного відділу, навіть юридичного, фінансового й рекрутингу, де на нього припадає 85-91% усіх відповідей. Не-розробники ростуть найшвидше, індивідуальних користувачів стало у 137 разів більше з серпня 2025. До червня 2026 найактивніші ганяють по 60 з гаком годин агентної роботи на день паралельними агентами. Поряд із цим Anthropic запустила Claude Tag, де задачу делегуєш, тегаючи Claude прямо в Slack, і він працює асинхронно на кількох людей. Обидві компанії, по суті, показують одне, робота зміщується від окремих питань до делегованих агентам довгих задач.
-
Google відкрив для всіх Interactions API в AI Studio, єдиний інтерфейс для застосунків на Gemini й агентах, де передаєш ідентифікатор моделі для відповіді або ідентифікатор агента для автономної задачі, є керовані агенти у віддалених пісочницях і фонове виконання. Він стає основним стандартом замість старого generateContent.
-
США і далі тримають руку на доступі до передових моделей. OpenAI відклала публічний реліз GPT-5.6 на прохання уряду США, відкривши доступ лише вузькому колу перевірених партнерів, чиї дані передали владі. Це за виконавчим указом, що дає уряду до 30 днів раннього доступу до передових моделей перед запуском, щоб шукати загрози від кібератак до військового застосування. Sam Altman каже, що тестування безпеки не зле, але йому не подобається, що клієнтів обирає уряд. А обмеження на моделі Anthropic, які США запровадили на початку місяця для негромадян, навпаки, почали знімати: 26 червня США відкрили Mythos 5 для понад 100 американських компаній і держустанов без окремої експортної ліцензії для затверджених.
-
Захоплені логи показали, як зловмисники зламують компанії через Claude і Codex. В понад тисячі сесій один атакувальник з Аддіс-Абеби автономно через AI вів розвідку, експлуатував вразливості й збирав паролі, маскуючи все під дозволені навчальні навчання, і зламав щонайменше 14 компаній. AI знижує поріг входу в атаки, дозволяючи новачкам діяти на рівні досвідчених.
-
Лобі дата-центрів каже, що Європі доведеться вибирати між AI і кліматичними цілями. Президент European Data Centre Association Lex Coors переконує, що мережа не готова, малі реактори не встигнуть, тож тимчасово може знадобитися новий газ, інакше Європа віддасть техсуверенітет Китаю. Єврокомісія хоче потроїти потужності дата-центрів до 2032. Кліматичні групи проти, бо новий газ лише закріплює залежність від викопного палива.
-
Amazon вийшов із прокату байопіку про Sam Altman. Готовий фільм Artificial від Luca Guadagnino з Andrew Garfield у головній ролі студія вирішила не випускати, і сталося це через чотири місяці після оголошення інвестиції Amazon в OpenAI на 50 мільярдів доларів. За інсайдерами, у фінальному монтажі Altman і Musk вийшли несимпатичними.
-
І наостанок, хтось побудував робочі обчислювальні схеми всередині Age of Empires II і довів, що гра обчислювально повна. Логічні елементи зробили з рельєфу, а носіями сигналу стали кози. Там навіть зібрали перцептрон для машинних передбачень.
Гарних вихідних.